Feelin' nearly faded as my jeans.
- Kris Kristofferson and Fred Foster
The Aztec Build System performs a multiple step compile process for each source code module. This model provides the ability to perform logic during the compile phase and alter the compile process accordingly. This is not a preprocessing language with limited logic capabilities; it is the same Aztec Programming Language syntax, and allows the compile-time logic to perform full mathematical expression evaluation, call methods, and perform all flow control statements (except exception handling).
The Aztec system also provides a variety of useful compile-time methods, including File I/O, User Interaction Dialogs, and many system level methods such as command line argument access, Aztec 'space' control, loading other Aztec source code modules (file or string), and writing information to the Compiler Log. A large set of compiler methods for primitive data type manipulation is also available. These methods are part of the Primitive Class Framework, which provides a consistent set of primitive methods across "compiler", "global" and "instance" scopes.
Every Aztec source code module is subjected to the following six step compile process.
♦ Module/Class Level Compiler Processing
♦ Step 1 – Parse the entire source code module (file or string) and perform initial level of syntax validation.
♦ Step 2 – Create data, methods and classes at module (type, class, data and method) and class level (data and method).
♦ Step 3 – Resolve all identifier usage at the module and class level.
♦ Step 4 – Execute eligible compile-time logic at the module and class level, which may include loading new Aztec source code modules for compilation.
♦ Method Level Compiler Processing
♦ Step 5 – Create data items at the method level (data and method).
♦ Step 6 – Resolve all identifier usage at the method level.
When processing multiple source code modules, the Aztec compiler weaves through these six steps across all source modules to achieve a very flexible approach to executing logic during the compile process. In general, the goal is to bring all source modules through the steps in as parallel a fashion as possible. This allows identifiers (type, class, data, method) created in one module (Step 2) to be immediately usable by global or class level code in another module (Step 3).
♦ For each source file specified on the Aztec Engine command line, perform Compiler Steps 1 and 2.
♦ For each source file, perform Step 3.
♦ Note that Steps 2 and 3 are not performed for blocks of statements that are part of module level and class level 'if' statements, at this time.
♦ For each source file, perform Step 4, which executes all compile-time logic at the module/script level.
♦ If a module level or class level 'if' statement is processed, the Aztec compiler determines which block of statements to include in the code based on the result of the boolean expression(s).
♦ The compiler then performs Steps 2, 3 and 4 specifically for this block of statements (and nested blocks). If more 'if' statements are nested inside, they are handled in the same way.
♦ If CompilerLoadModule() was called during Step 4, repeat Compiler Steps 1 - 4 for each module in this new queued source module list.
♦ Queued source files are processed in the same "weaving" manner as described above for original source modules (all queued modules go through Steps 1 and 2 before any go through Step 3, etc.).
♦ Repeat this entire process until there are no more queued source modules to process. There is no limit to the number of nested levels with CompilerLoadModule() calls.
♦ For each source file (cumulative), perform Step 5.
♦ For each source file, perform Step 6.
♦ For each source file, create Aztec Virtual Machine binary executable code.
Data and methods can be defined to work within the compile-time logic phase (Step 4) and together with access to full mathematical expression evaluation, provide a very flexible system for performing logic during the compile phase.
♦ Data items marked as 'compiler' are available for full expression evaluation at compile-time, and can also be the target of an assignment at the module/class level during compile-time logic.
♦ Only primitive objects can be specified as 'compiler', and arrays of compiler variables are currently not allowed.
♦ Primitive reference variables can also be used as compiler variables and they can be passed as arguments to compiler methods.
♦ A 'compiler' variable becomes a standard global variable when the Script/Application is executed, and it can be used within expressions inside methods as normal.
♦ The final value that the compiler variable had during compile-time logic is carried over as an initial value to the Virtual Machine for run-time.
♦ If marked as 'const', the variable cannot be the target of an assignment at run-time (inside a "normal" method, for instance). However, a 'const' can be modified at compile-time if also marked as 'compiler'.
♦ The 'const' attribute for a variable applies to run-time. This functionality provides the flexibility to determine the appropriate value for the constant dynamically at compile-time and easily assign it.
Methods marked as 'compiler' are available to be called during compiler-time logic only. Compiler methods and all of the statements inside the compiler method follow standard Aztec syntax rules. As mentioned above, full expression evaluation is also available inside compiler methods.at compile-time.
♦ A compiler method can contain default arguments, and an argument can be a primitive value or a primitive reference. The method can also return a primitive value or reference.
♦ A compiler method can be used as a "method call statement" or inside an expression at the module/class level and inside a compiler method.
♦ A compiler method cannot be called from within a normal method or within an initialization expression for a "normal" data item (global or class level).
♦ Exception handling and the exceptions/handle construct are not supported during compile-time logic.
During Step 4, certain statements can be executed in order to implement compile-time logic and processing. The following statement types are allowed.
♦ The Assignment statement is allowed at the module level, inside classes and inside compiler methods. The target of the assignment must be a valid identifier defined with ‘compiler’ keyword, all terms in the expression must be resolved at the time of "execution", and each data item must be marked as ‘const’ or ‘compiler’, explicitly or implicitly.
♦ Module and class level data items must be manually marked as 'const' or 'compiler'.
♦ Data items defined inside a compiler method are marked as 'compiler' automatically.
♦ The Method Call statement is allowed at the module level, inside classes and inside compiler methods. The method being executed must be marked as ‘compiler’ and args are validated as above.
♦ The ‘if’ statement is allowed at the module level and inside classes. For ‘if’ statements at the module level, classes, data items, methods, types and enumerations can be contained within the ‘if' logic. For 'if' statements at the class level, data items and method can be contained within the 'if' logic.
♦ All Aztec flow control statements are supported within compiler methods, except exceptions/handle. Exceptions are not supported at compile-time. The Compiler will terminate in error if an internal exception occurs.
♦ When evaluating expressions during compile-time logic, each compiler method is executed dynamically and the return value is used in the expression at that time.
♦ Method references and arrays are currently not supported during compile-time processing, though these options are being considered for a future release.
As mentioned above, compiler methods can only be used during compile-time processing (compiler step 4). Compiler data items, however, can bridge the gap between compile-time processing and run-time prrocessing. A global data item marked as 'compiler' can be set during compile-time execution, and that same global 'compiler' variable becomes a "normal" run-time variable in the Virtual Machine, and its value is carried over from the compile-time logic.
The Aztec system provides a library of “compiler” methods for use during Step 4 as described above. In addition to methods for manipulating primitive data (see Primitive Classes), features also include text file I/O, displaying dialogs, accessing system time, compiler flags and space. The following tables show the Aztec compiler methods for System, File I/O and Dialog services.


There are three ways to compile Aztec source modules and integrate them into the Virtual Machine Metadata environment. The same multiple step compiler methodology as defined above is used in all three of these approaches.
♦ Specify one or more source files on the Aztec Engine command line. Source code is in a file only.
♦ Call CompilerLoadModule() during Step 4 of the compile-time logic. Source code can be in a file or a string.
♦ Call Script.LoadModule() at run-time. Source code can be in a file or a string.
The following bullets describe two interesting use cases for compile-time logic, combined with the ability to dynamically create source code for the CompilerLoadModule() method. In both cases, the input data files are absorbed into the Aztec bytecode executable file, so they are not needed at run-time. A single executable file (.azcode) can be distributed to users, and the contents of the input files is already embedded in the file based on the approaches described below.
♦ Process application Help files at compile time and embed them in the Aztec binary executable file.
♦ Read the contents of a Help file (or any other type of ASCII input file) using the Compiler Text I/O Methods and create one string that contains the entire file.
♦ Assign this string to a "compiler" variable, so the "value" of the string (contents of the file) is persistent in the byte code file and is used to initialize the variable at run-time.
♦ This string can then be parsed as necessary at run-time. A large library of string parsing methods is available at compile-time.
♦ General approach to reading and parsing data files and creating Aztec array objects with the data. This is a more detailed approach than the previous Help file example, but it ends up creating an array of Aztec objects that is more directly usable at run-time.
♦ The high level plan is to dynamically create source code syntax for the definition of a global array of objects with initialization of those objects, and then compile the code to create the array.
♦ Read the contents of a Data file using the Compiler Text I/O Methods and parse each record according to the format specifications of the data
♦ Build up the array initialization based on the contents of the data file and the definition of the class used in the array.
♦ When the entire data definition statement is embedded in a string, along with the initialization data, the CompilerLoadModule() method is called, with the "IsFile" argument set to false.
♦ CompilerLoadModule() supports the source code module being in a file or in a string, so the behavior is identical to how it would work for a file. The module code (string in this case) is queued up to be compiled based on the rules described above.
♦ The example script down below presents a simple version of this approach.
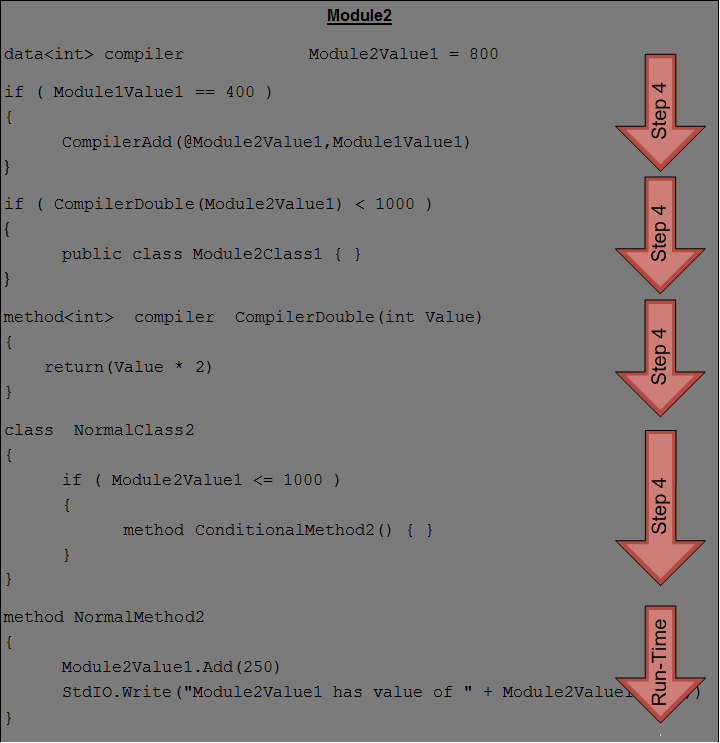
The following diagrams show a simple example using compile-time logic. The labels indicate where the compiler is responsible for executing the code (Step 4) and where the Virtual Machine is responsible for executing the code (Run-Time). In this case, Module1 is specified on the Aztec Engine command line, and it will be compiled from Steps 1 - 4, including compile-time logic. If the boolean condition is true, Module2 is loaded during Step 4 for Module1. If that occurs, the compiler then performs Steps 1 - 4 for Module2. It then finishes up by performing Step 5 for each of the modules, followed by Step 6 for each of the modules. Steps 5 and 6 focus on creating and resolving identifiers inside normal methods. As discussed above, once Step 6 is complete for all modules, the system creates Virtual Machine binary bytecode, which is then either written to an executable file (-comp) or is passed to the Virtual Machine for execution (-exec).

♦ There are a number of example scripts showing the use of Compile-Time Logic, including the "Why Aztec - Compile-Time Logic" page and most of the flow control pages.
